Yang Miao
Researcher in Computer Vision and Robotics at INSAIT
Home
Publications
Selected Projects
CV
Links
Contact
Papers under Review
Published Papers
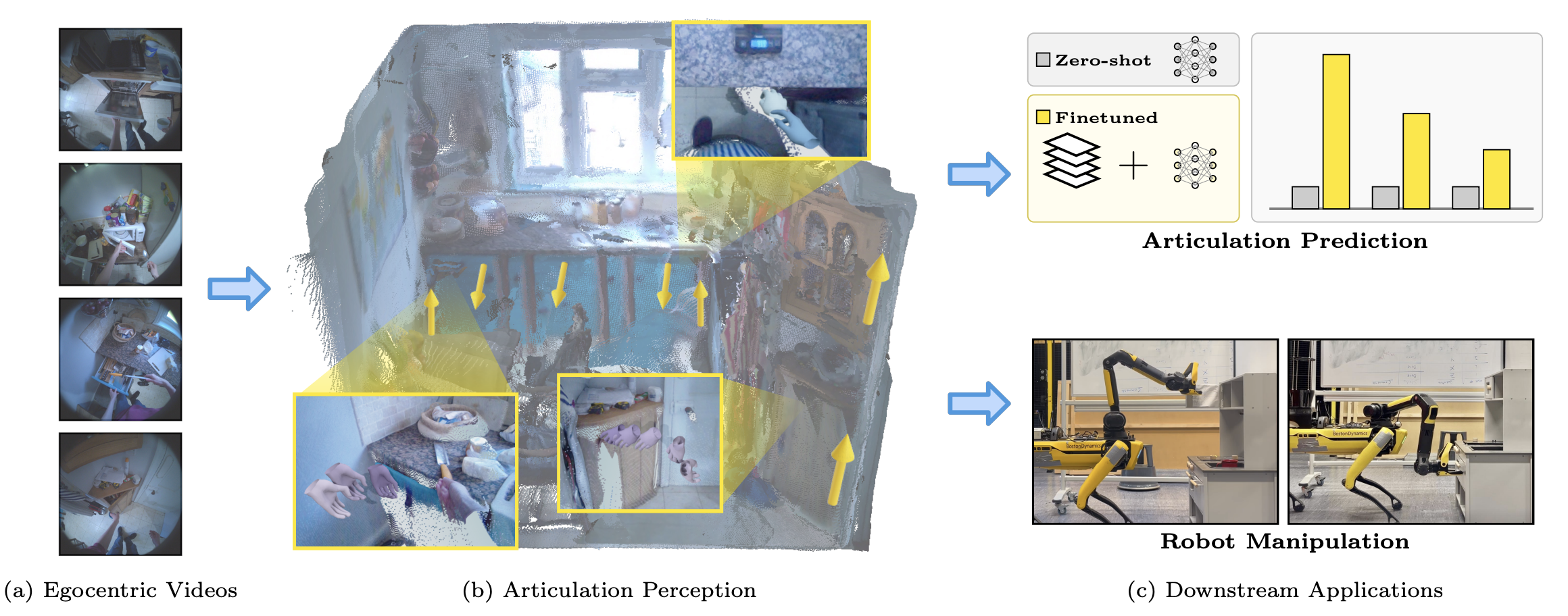
PAWS: Perception of Articulation in the Wild at Scale from Egocentric Videos
Articulation perception aims to recover the motion and structure of articulated objects (e.g., drawers and cupboards), and is fundamental to 3D scene understanding in robotics, simulation, and animation. Existing learning-based methods rely heavily on supervised training with high-quality 3D data and manual annotations, limiting scalability and diversity. To address this limitation, we propose PAWS, a method that directly extracts object articulations from hand–object interactions in large-scale in-the-wild egocentric videos. We evaluate our method on the public data sets, including HD-EPIC and Arti4D data sets, achieving significant improvements over baselines. We further demonstrate that the extracted articulations benefit downstream tasks, including fine-tuning 3D articulation prediction models and enabling robot manipulation. Code and data sets will be released upon acceptance.
Authors: Yihao Wang*, Yang Miao*, Wenshuai Zhao, Wenyan Yang, Zihan Wang, Joni Pajarinen, Luc Van Gool, Danda Pani Paudel, Juho Kannala, Xi Wang, Arno Solin (* equal contribution)
[preprint] [webpage]
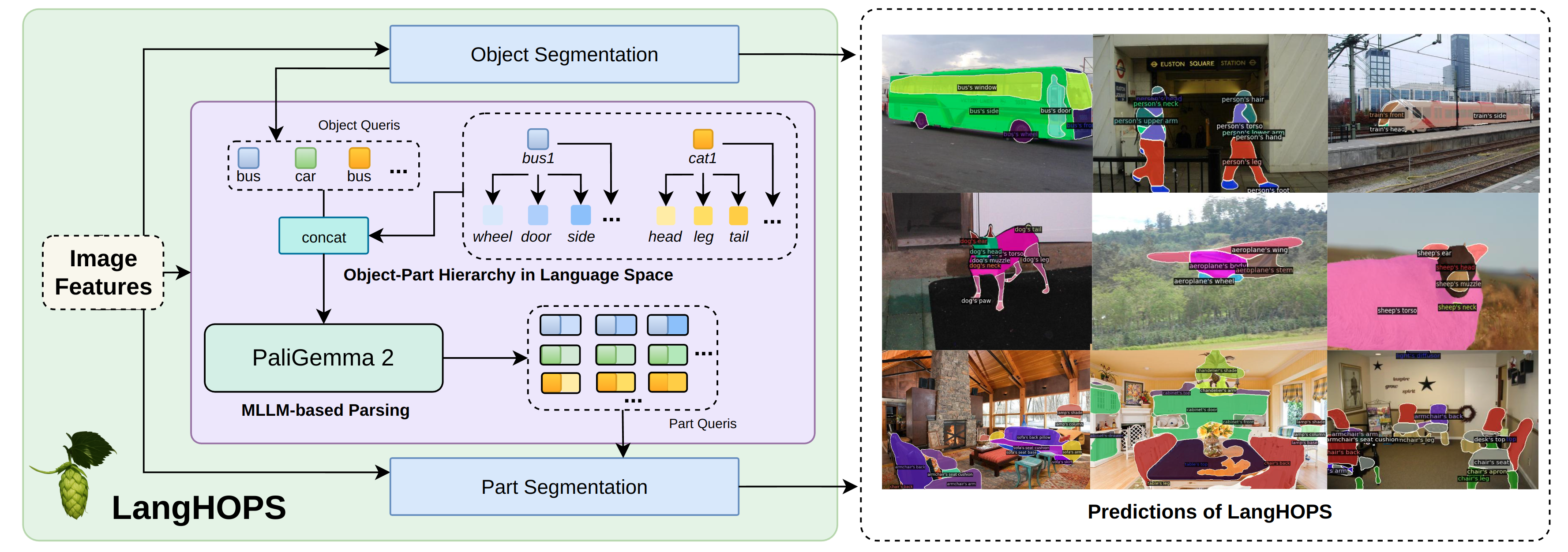
LangHOPS: Language Grounded Hierarchical Open-Vocabulary Part Segmentation
We propose LangHOPS, the first Multimodal Large Language Model~(MLLM)-based framework for open-vocabulary object–part instance segmentation. Given an image, LangHOPS can jointly detect and segment hierarchical object and part instances from open-vocabulary candidate categories. Unlike prior approaches that rely on heuristic or learnable visual grouping, our approach grounds object–part hierarchies in language space. It integrates the MLLM into the object-part parsing pipeline to leverage its rich knowledge and reasoning capabilities, and link multi-granularity concepts within the hierarchies.
Authors: Yang Miao, Jan-Nico Zaech, Xi Wang, Fabien Despinoy, Danda Pani Paudel, Luc Van Gool
NeurIPS 2025
[preprint] [webpage]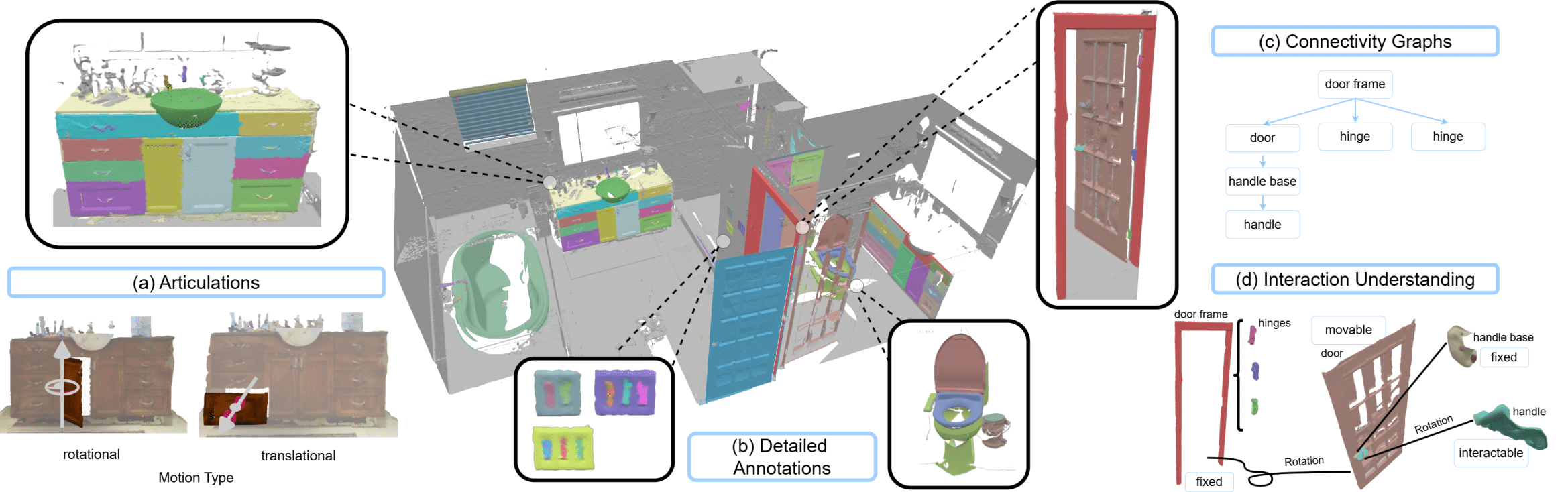
Articulate3D: Holistic Understanding of 3D Scenes as Universal Scene Description
We propose Articulate3D, an expertly curated dataset in the Universal Scene Description (USD) format, featuring high-quality manual annotations, for instance, segmentation and articulation on indoor scenes. Also, we come up with USDNet, a learning-based model together with a novel baseline capable of predicting part segmentation along with a full specification of motion attributes, including motion type, articulated and interactable parts, and motion parameters.
Authors: Anna-Maria Halacheva*, Yang Miao*, Jan-Nico Zaech, Xi Wang, Luc Van Gool, Danda Pani Paudel (* equal contribution)
ICCV 2025
[preprint] [code] [webpage] [challenge]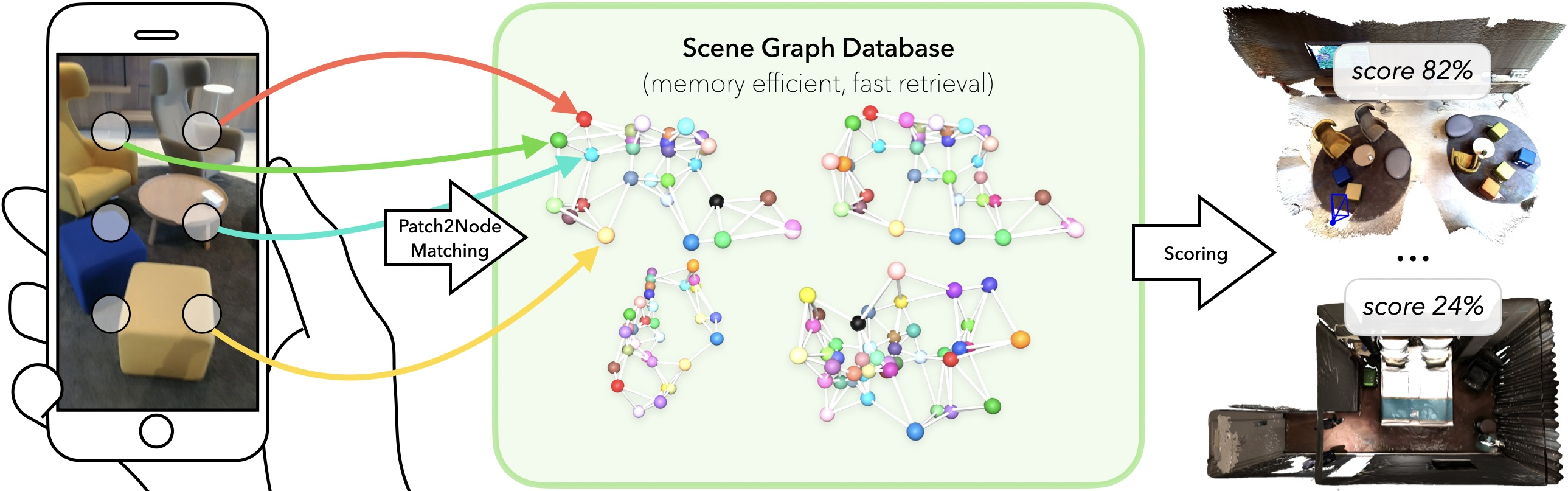
SceneGraphLoc: Cross-Modal Coarse Visual Localization on 3D Scene Graphs
We introduce a novel problem, i.e., the localization of an input image within a multi-modal reference map represented by a database of 3D scene graphs. These graphs comprise multiple modalities, including object-level point clouds, images, attributes, and relationships between objects, offering a lightweight and efficient alternative to conventional methods that rely on extensive image databases. Given the available modalities, the proposed method SceneGraphLoc learns a fixed-sized embedding for each node (i.e., representing an object instance) in the scene graph, enabling effective matching with the objects visible in the input query image. This strategy significantly outperforms other cross-modal methods, even without incorporating images into the map embeddings. When images are leveraged, SceneGraphLoc achieves performance close to that of state-of-the-art techniques depending on large image databases, while requiring three orders-of-magnitude less storage and operating orders-of-magnitude faster. The code will be made public.
Authors: Yang Miao, Francis Engelmann, Olga Vysotska, Federico Tombari, Marc Pollefeys, Daniel Barath
ECCV 2024
[preprint] [video] [webpage]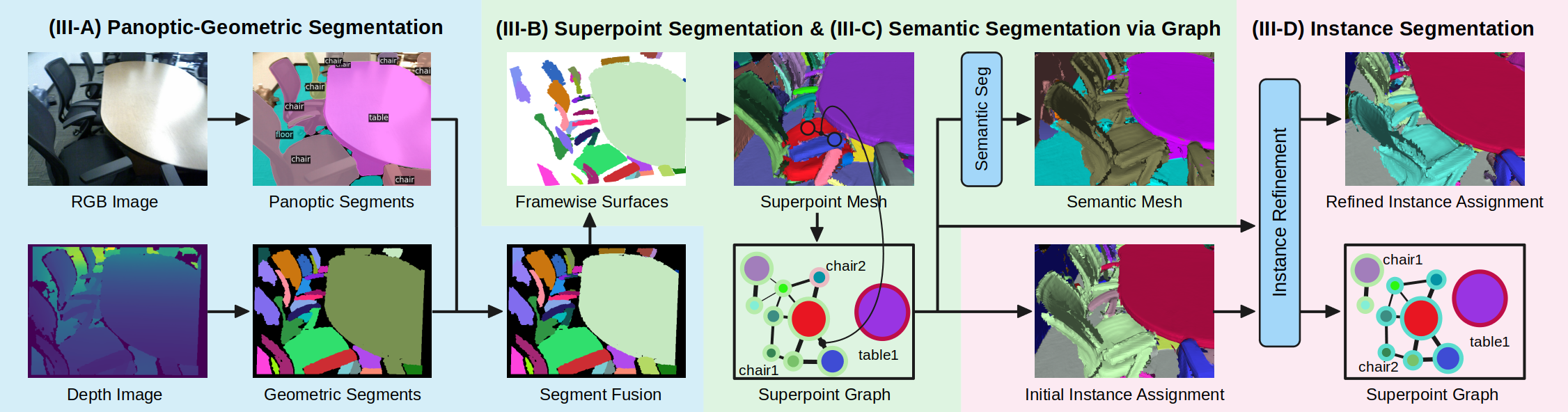
Volumetric Semantically Consistent 3D Panoptic Mapping
We introduce an online 2D-to-3D semantic instance mapping algorithm aimed at generating comprehensive, accurate, and efficient semantic 3D maps suitable for autonomous agents in unstructured environments. The proposed approach is based on a Voxel-TSDF representation used in recent algorithms. It introduces novel ways of integrating semantic prediction confidence during mapping, producing semantic and instance-consistent 3D regions. Further improvements are achieved by graph optimization-based semantic labeling and instance refinement. The proposed method achieves accuracy superior to the state of the art on public large-scale datasets, improving on a number of widely used metrics. We also highlight a downfall in the evaluation of recent studies: using the ground truth trajectory as input instead of a SLAM-estimated one substantially affects the accuracy, creating a large gap between the reported results and the actual performance on real-world data.
Authors: Yang Miao, Iro Armeni, Marc Pollefeys, Daniel Barath
IROS 2024 (Oral Pre)
[preprint] [video] [code]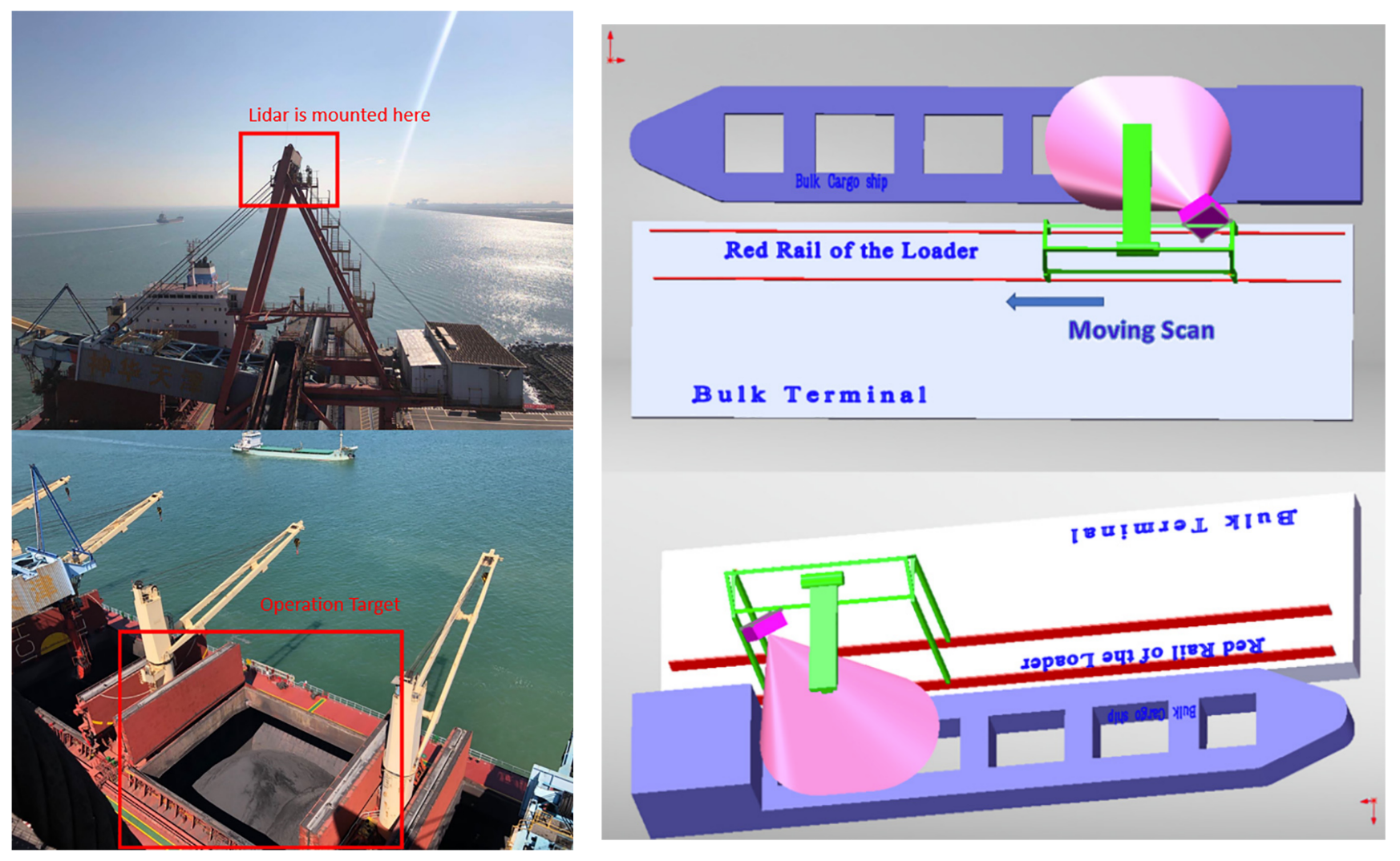
3D Computer Vision for Automation of Port Operations
Achieving port automation of machinery at bulk terminals is a challenging problem due to the volatile operation environments and complexity of bulk loading compared to the situations in container terminals. In order to facilitate port automation, we present a method of hull modeling (reconstruction of hull’s structure) and operation target (cargo holds under loading) identification based on 3D point cloud collected by Laser Measurement System mounted on the ship loader. In the hull modeling algorithm, we incrementally register pairs of point clouds and reconstruct the 3D structure of bulk ship’s hull blocks in details through process of encoder data of the loader, FPFH feature matching and ICP algorithm. In the identification algorithm, we project real-time point clouds of the operation zone to spherical coordinate and transforms the 3D point clouds to 2D images for fast and reliable identification of operation target. Our method detects and complements four edges of the operation target through process of the 2D images and estimates both posture and size of operation target in the bulk terminal based on the complemented edges. Experimental trials show that our algorithm allows us to achieve the reconstruction of hull blocks and real-time identification of operation target with high accuracy and reliability.
Authors: Yang Miao, Changan Li, Zhan Li, Yipeng Yang, Xinghu Yu
Measurement and Control, 2021
[pdf]